Введение
Авторы поставили перед собой задачу помочь системному администратору в выборе нереляционной СУБД [1], которая будет оптимальна при решении конкретной прикладной задачи в 2022 году.
В данном обзоре мы рассматриваем наиболее часто используемые СУБД [2]: MongoDB [3], Redis, Cassandra, Elasticsearch и Firebase (по данным за 2021 год). Сосредоточив внимание на их преимуществах и недостатках, связанных с реальным практическим использованием, постараемся очертить сферу рационального применения для каждой из них.
В прошлой статье авторов уже были рассмотрены самые известные и широко рекламируемые реляционные СУБД. Данный обзор посвящён нереляционным СУБД, с которыми чаще всего приходится иметь дело специалистам в прикладных задачах. Популярность СУБД определялась согласно анализу результатов [4] опроса специалистов, работающих в сфере информационных технологий, проведённого в конце 2021 года. Таким образом, основываясь на изложенных данных, можно прогнозировать наиболее предпочтительные нереляционные СУБД для внедрения в 2022 году.
Возможно, вам также будет интересно описание реляционных СУБД? Обратите внимание на нашу статью Анализ популярных реляционных систем управления базами данных.
Теоретическая часть
В настоящее время распространены два основных типа СУБД: реляционные и нереляционные, называемые SQL и NoSQL соответственно. Рассмотрим, чем отличаются реляционные и нереляционные СУБД с учетом структуры, производительности, масштабируемости и безопасности.
Нереляционные базы данных известны своей высокой производительностью, обеспечивая одновременный доступ большому количеству пользователей. Могут хранить неограниченное количество наборов данных всех типов и форм. Они достаточно гибки, когда речь идёт об изменении типов данных. Однако, СУБД NoSQL имеют относительно низкую безопасность, что является негативным фактором для многих инфраструктур.
Поскольку CУБД типа NoSQL позволяют одновременно резервировать различные типы данных и масштабировать их, функционируя на нескольких серверах одновременно, их популярность понятна. Кроме того, создание MVP (минимально жизнеспособных продуктов [5]) — это отличный вариант для стартапов с гибкой технологией разработки. NoSQL не требует предварительной подготовки к развертыванию, что упрощает быстрое обновление структуры данных [6] без задержек по времени.
В предыдущей статье мы рассмотрели реляционные СУБД:
• MySQL
• MariaDB
• Oracle 12с
• PostgreSQL
• MSSQL
В настоящем обзоре сфокусируемся на решениях NoSQL:
• MongoDB
• Redis
• Cassandra
• Elasticsearch
• Firebase
Диаграмма на рис. 1. отражает несколько популярных нереляционных с точки зрения практического внедрения или использования СУБД.

Рис. 1. Самые популярные нереляционные системы управления базами данных.
Основные характеристики самых распространённых СУБД приведены в Табл. 1.
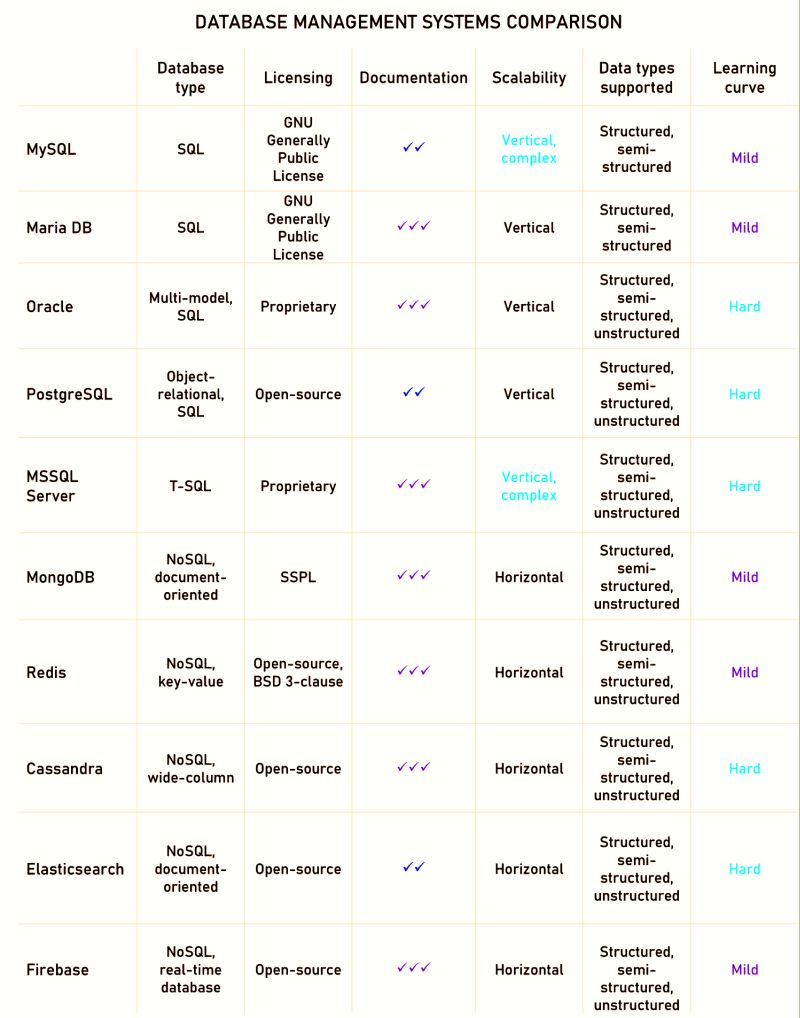
Табл. 2. Краткая таблица сравнительных характеристик СУБД
Ниже рассмотрим современные СУБД, выделяя достоинства и недостатки, а также типовые варианты использования.
MongoDB
Бесплатная, с открытым исходным кодом, нереляционная СУБД, MongoDB имеет и коммерческую версию. Хотя MongoDB изначально не предназначалась для обработки структурированных данных, эту СУБД можно применять для приложений, которые используют как структурированные, так и неструктурированные данные. В MongoDB базы данных подключаются к приложениям через драйверы баз данных. Несколько типов данных обрабатываются одновременно и для этой цели используется внутренний кэш.
Плюсы MongoDB
1) Простой доступ к данным, их хранение, ввод и извлечение. Одним из преимуществ MongoDB, вытекающих из его природы NoSQL, является быстрая и простая обработка данных. То есть данные могут быть введены, сохранены и удалены из БД быстро и без какого-либо дополнительного подтверждения. Как и в любой другой нереляционной базе данных, особое внимание уделяется использованию оперативной памяти, поэтому с записями можно работать очень быстро и без каких-либо последствий для целостности данных.
2) Простая совместимость с другими моделями данных. MongoDB легко сочетается с различными системами управления базами данных, как SQL, так и NoSQL. Кроме того, имеет подключаемые API-интерфейсы механизма хранения - эта опция позволяет третьим сторонам создавать свои собственные механизмы хранения данных для MongoDB. С коммерческой точки зрения это создает дополнительную ценность для ПО, ориентированного на бизнес.
3) Горизонтально масштабируемое решение. Масштабируемость – это фундаментальный аспект природы MongoDB. Этот нюанс становится еще более важным для предприятий, работающих с приложениями больших данных. Кроме того, БД может быстро и сбалансированно распределять данные по кластеру. Поскольку это приводит к более быстрой обработке данных, производительность приложения ощутимо повышается.
Минусы MongoDB
1) Большое потребление памяти. Процесс денормализации, когда ранее нормализованные данные в БД группируются для повышения производительности, обычно приводит к высокому потреблению памяти. Кроме того, эта СУБД хранит в памяти все имена ключей для каждой пары значений. Кроме того, из-за отсутствия поддержки объединений в БД наблюдается переизбыток данных, что приводит к утечке памяти и снижению производительности приложений.
2) У MongoDB нет связей между документами и «коллекциями» (частично это компенсируется Database Reference — ссылками в СУБД, но это не полностью решает проблему). В итоге, может возникнуть ситуация, при которой имеется некий набор данных, который никак не связан с другой информацией в базе, и не существует никакого способа объединить данные из различных документов. В SQL-системах это было бы элементарной задачей.
3) Защищенность. Ориентируясь на быструю работу с данными, MongoDB, как и любой представитель типа NoSQL, не обеспечивает безопасность данных. Поскольку аутентификация пользователя не является опцией по умолчанию, а более высокая защита доступна только в коммерческой версии, нельзя считать ее полностью безопасной.
4) Сложный процесс для перевода на другие языки запросов. Поскольку MongoDB изначально не была предназначена для работы с реляционными моделями данных, производительность в этих случаях может снизиться. Кроме того, перевод SQL-запросов в MongoDB требует дополнительных действий для использования движка, что может затормозить разработку и развертывание.
5) Медленное восстановление БД после аппаратных сбоев.
MongoDB лучше всего подходит для интеграции данных в реальном времени и масштабируемости базы данных. Например, это хороший выбор для каталогов продуктов из-за способности хранить множество объектов с различными коллекциями атрибутов. Кроме того, стоит упомянуть аналитические платформы, поскольку скорость MongoDB обеспечивает динамическую производительность, которая может помочь отслеживать поведение пользователя в режиме реального времени.
Redis
СУБД с открытым исходным кодом, разновидность NoSQL, Redis может использоваться в качестве кэша [7], когда требуется сверхбыстрый доступ к данным. Используются пары ключ-значение. Отличительной особенностью является то, что существует несколько вариантов структурирования данных, таких как списки, наборы и хэши.
Позволяя выполнять репликацию данных и поддерживать транзакции, Redis выполняет команды в очереди, а не устанавливает их по одной за раз.
Плюсы Redis
1) Быстрое решение. Благодаря своим уникальным функциям репликации и транзакций Redis обрабатывает данные очень быстро. Отсутствие зависимостей и типа хранилища данных в памяти делает Redis достойным конкурентом даже среди простых альтернатив SQL.
2) Массовая обработка данных. Возможность загружать до 1 ГБ данных для одной записи. А встроенное кэширование данных позволяет без серьёзных затрат получить мощный сервер баз данных.
Минусы Redis
1) Зависимость от объёма памяти. Полная зависимость от оперативной памяти является реальным недостатком. То есть БД выйдет из строя, если ее размер превысит размер доступной памяти.
2) Нет поддержки языка запросов или объединений. Что касается совместимости с другими типами наборов данных, Redis уступает конкурентам. Учитывая, что в какой-то момент вашему бизнесу может потребоваться масштабирование и использование других форматов данных, возможность быстрого ввода в качестве единственного варианта оставляет эту проблему открытой.
У Redis есть несколько типовых областей применения, но объединяет их требование крайне быстрого доступа к данным. Если создается ресурс для электронной коммерции, в котором есть подгружаемые на каждой странице категории, то вместо обращения к БД при каждом чтении, что весьма затратно, можно хранить данные в кэше. В результате получается быстро осуществлять операции чтения/записи. Зачастую рекомендуется применять СУБД, такие как Redis, использующие кэш, в качестве оболочки для обработки часто запрашиваемых данных, избавляющей от необходимости совершения частых запросов к самой БД. Это решение можно увидеть и в применении для интернета вещей: здесь большие объемы данных с устройств интернета вещей могут быть переданы в Redis для обработки этих записей, прежде чем поместить их в долговременное хранилище данных. Кроме того, Redis является идеальным вариантом для микросервисных архитектур с масштабируемым облачным хостингом. Поскольку данные здесь не обязательно должны быть долговременными, Redis выступает рациональным решением.
Cassandra
Cassandra — это децентрализованная система, разработанная компанией Apache, бесплатная СУБД на базе Java, особенность которой заключается в ее функциях множественной репликации и множественного развертывания. Будучи быстро масштабируемой, Cassandra позволяет управлять большими объемами данных, реплицируя их на несколько узлов. Это устраняет проблему сбоя БД – если какой-либо из узлов в любой момент выходит из строя, он немедленно заменяется, и система продолжает работать до тех пор, пока хотя бы один узел находится в стабильном состоянии.
Cassandra использует свой собственный язык запросов CQL. По своему синтаксису он очень похож на SQL, но не применяет объединения, заменяя их так называемыми семействами столбцов. Второе отличие заключается в том, что не все столбцы в таблице хранятся для подзапросов. Некоторые из них используются в качестве столбцов кластеризации, где смежные данные помещаются рядом друг с другом для быстрого извлечения. Такой подход обеспечивает ускоренную выборку из объёмных наборов данных, ускоряя обработку данных таким образом.
Плюсы Cassandra
1) Безопасность данных. Благодаря функции репликации Cassandra является весьма отказоустойчивой. Можно быть уверенным в безопасности данных до тех пор, пока все главные узлы не выйдут из строя одновременно. Иначе, СУБД и БД будут оставаться надежными и безопасными.
2) Гибкость и внесение изменений. Простой синтаксис Cassandra впитал в себя лучшее из идеологий SQL и NoSQL. В дополнение к масштабируемости, это в значительной степени способствует гибкости набора данных. Cassandra собирает данные на ходу, и поиск данных отличается такой же простотой, несмотря на размер набора данных. Это позволяет максимально увеличивать БД.
Минусы Cassandra
1) Медленное чтение. Поскольку Cassandra изначально была предназначена для скоростной записи, ее слабость заключается в неспособности к быстрому чтению.
2) Потребность в дополнительных ресурсах. Поскольку Cassandra обрабатывает несколько слоев данных одновременно, для этого требуются серьёзные вычислительные ресурсы. На практике это приводит к дополнительным вложениям как в ПО, так и в аппаратное обеспечение.
СУБД Cassandra используется для хранения последовательных данных, логов, или огромного объема информации, который может генерироваться автоматически или путём измерений — к примеру, каким-либо датчиками [5]. Если разработчики собираются использовать СУБД для записи больших массивов данных и при этом планируется, что будет явно меньше обращений на чтение, и данные могут не иметь связи и объединения, тогда Cassandra будет оптимальным выбором.
Благодаря равномерному распределению данных, Cassandra актуальна в приложениях, где обрабатываются большие объемы информации. Например, востребованное решение для центров обработки данных. Кроме того, Cassandra хорошо подходит для аналитики в реальном времени, поскольку позволяет линейно масштабировать и увеличивать данные в реальном времени. Ещё вариант: для приложений с постоянной потоковой передачей данных, таких как погодные приложения. Другой вариант - использовать в качестве СУБД для магазина электронной коммерции, поскольку будет удобно хранить историю покупок и другие транзакции. Добавьте сюда возможность отслеживания таких типов данных, как статус заказа и пакеты, и вы получите полное решение с интеграцией доставки для электронной коммерции.
Elasticsearch
Elasticsearch — это архитектура NoSQL, ориентированная на документы СУБД, в основе которой лежит полнотекстовая поисковая система. Построенный на базе библиотеки Apache Lucene, она хранит данные в виде файла JSON, поддерживает API RESTful и использует мощный аналитический механизм для более быстрого извлечения данных. Будучи программным обеспечением с открытым исходным кодом, она включает в себя как бесплатные, так и платные версии.
Плюсы Elasticsearch
1) Масштабируемая архитектура. Одной из особенностей Elasticsearch является надежная распределенная архитектура. Ключевые параметры структуры, такие как кластеризация, индексирование, сегментирование и многие другие, обеспечивают широкое горизонтальное масштабирование, что позволяет размещать терабайты записей с дальнейшей автоматизацией. Уровни абстракции архитектуры упрощают управление системой как на индивидуальном, так и на совокупном уровнях.
2) Быстрая обработка данных. Благодаря распределенной структуре данных и встроенному распараллеливанию база данных Elasticsearch показывает отличные результаты производительности. Даже при выполнении сложного запроса данных, она генерирует ответы на результаты поиска lightning. Это частично доступно благодаря тому, что документы хранятся рядом с соответствующими метаданными в индексе, что позволяет быстро находить их.
Минусы Elasticsearch
1) Отсутствие мульти-языковой поддержки. Поддерживаются только форматы документа JSON.
2) Ограниченные инструменты мониторинга. В случае возникновения внештатно ситуации, может оказаться что данная СБУД не имеет инструментов отчетности. Хотя проблемы обычно связаны с ограниченным объёмом памяти или емкостью диска, администраторы часто жалуются на ситуацию.
В случае необходимости осуществления полнотекстового поиска по БД (например, поиск продукции на ресурсе для электронной коммерции), хорошим решением будет использование поисковой СУБД вроде ElasticSearch. Эта система способна быстро осуществлять поиск по огромному массиву данных и обладает обширной функциональностью — например, СУБД умеет осуществлять поиск по именованным категориям.
Firebase
Принадлежащая Google, СУБД Firebase — это серверная часть как служба, используемая для разработки веб- и мобильного программного обеспечения. Вообще, существует два варианта: база данных Firebase (обеспечивает доступ в режиме реального времени к данным, находящимся на разных платформах) и облачный магазин Firestore (обеспечивает большую масштабируемость и более сложные модели данных). Таким образом, оба решения прекрасно вписываются в сценарий, когда нужно иметь дело с большим количеством данных в режиме реального времени: изменения в БД извлекаются по мере их возникновения.
Плюсы Firebase
1) Низкий порог вхождения. Firebase может быть отличным вариантом для быстрого старта.
2) Удобный доступ к данным, удобное управление. Через консоль обеспечивается легкого доступ к данным. Являясь одновременно облачными решением и обладая архитектурой NoSQL, СУБД обеспечивает достаточную гибкость и масштабируемость при увеличении объема данных. Кроме того, Firebase позволяет работать с адаптивными приложениями и обновлять данные даже при отсутствии подключения к Интернету.
3) Проработанная документация. Документация включает в себя рекомендации, техническую документацию, ссылки на SDK, информацию об интеграции и многое другое. Сообщество развито, что позволяет легко находить ответы на возникающие проблемы.
Минусы Firebase
1) Ограниченные возможности запроса. Проблема проявляется в ограниченности в выполнении простых запросов, так как для более сложных нет возможностей фильтрации. Это связано с тем, что вся БД представляет собой консолидированный файл формата JSON без каких-либо опций для моделирования данных.
2) Ограниченная миграция данных. Перенос данных на другую платформу может потребовать серьёзных усилий. Отсутствуют инструменты миграции для передачи данных или установки БД проекта по умолчанию.
СУБД Firebase рекомендуется использовать, когда ПО имеет дело с данными в реальном времени, которые необходимо синхронизировать между различными браузерами и устройствами. Типовой выбор: приложения для обмена сообщениями, приложения для социальных сетей и игровые приложения.
Субъективное сравнение СУБД
Следующая гистограмма (рис. 2) показывает, какой процент специалистов желает/избегает работать с конкретной СУБД.
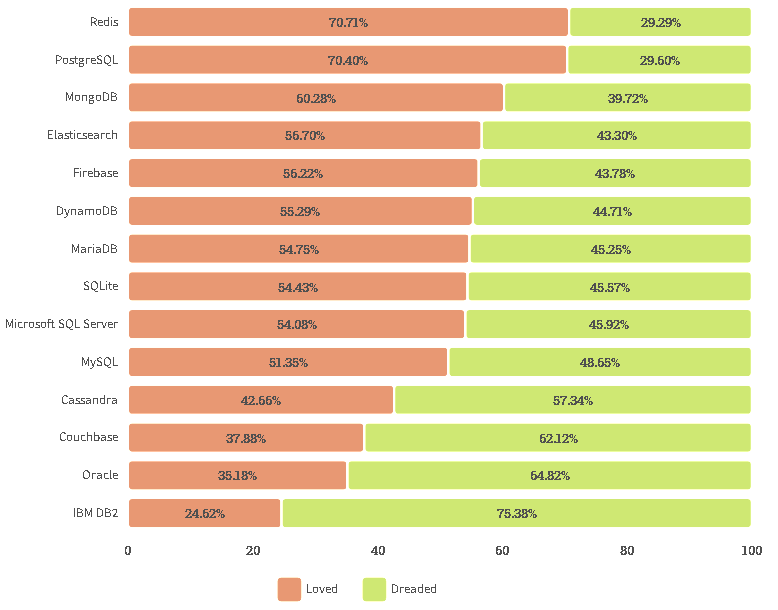
Рис. 2. Объективная оценка удобства использования самых часто используемых СУБД.
Нереляционная СУБД Redis уже пятый год является самой любимой и востребованной СУБД, с которой удобно работать, как считают специалисты. Однако, реляционная PostgreSQL чисто символически уступает полпроцента. А такая мощная и весьма известная [1] СУБД как IBM DB2 второй год подряд является системой, которую стремится избегать большинство.
Кроме того, из практики авторы могут привести примеры практического внедрения и любопытные результаты.
1) Переход с MS SQL на PostgreSQL (под Linux) оказался оправданным решением для высоконагруженных проектов (размер БД свыше 1 Тб). Это привело к повышению производительности, высвобождению ресурсов и упрощению обслуживания. В течение последних трёх лет данная тенденция остаётся неизменной.
2) Переход с MariaDB на MySQL полностью оправдывает себя, что показали примеры с несколькими веб-сайтами. Несмотря на то, что непосредственно перенос БД в другую СУБД зачастую оказывается непростым мероприятием, дальнейшая простота в обслуживании и стабильность явно того стоят.
3) Дополнительное кэширование средствами Redis может дать десятикратный прирост производительности для старого высоконагруженного сайта.
Из авторской практики следует привести в качестве примера один из интересных вариантов выбора и внедрения. В одном из проектов для полнотекстового поиска был применён Redisearch (надстройка над Redis), и через какое-то время стал очевидным недостаток - для Redis работает правило, что все данные должны храниться в ОЗУ. В результате пришлось менять структуру проекта и использовать ElasticSearch, благо у него более мощный язык поиска данных и репликация реализована без дополнительных настроек.
4) Ещё интересный случай из авторской практики: на самом старте проекта была применена СУБД MongoDB без шардирования, а с развитием проекта оказалось, что производительности начинает не хватать. Возникла необходимость выбирать критерии шардирования. Выбор был сделан вынужденно неоптимально, т.к. к этому моменту БД успела вырасти до неудобных размеров (8 Тб). Был сделан вывод о том, что подобными вопросами следовало озаботиться при дизайне системы.
5) Наконец, из опыта авторов следует упомянуть интересную ситуацию использования базовых возможностей СУБД, которые показали себя максимально эффективно. В одном из проектов была применена СУБД MongoDB в базовом варианте репликации на 3 копии. Когда произошёл серьёзный аппаратный сбой и была физически уничтожена треть кластера, на работоспособности всей системы это не сказалось ни коим образом.
Выводы и заключение
Существует большое количество СУБД, не описанных в данной статье. В частности, есть функциональные СУБД отечественной разработки [1], которые не вошли в настоящий обзор только лишь потому, что не являются популярными с точки зрения повсеместного внедрения. Настоящая статья является сравнительным обзором самых часто используемых СУБД. Каждая СУБД по-своему хороша, но имеет и некоторые недостатки.
Однозначно посоветовать правильный выбор для новых проектов или для будущего перехода не представляется возможным. Попробуем в общих чертах дать рекомендации по выбору.
Для разработки интернет-мгазина логично рассмотреть СУБД Cassandra. Чтобы дополнить эту СБУД мощной поисковой системой, рационально подключить Elasticsearch.
Особенность Cassandra заключается в том, что это заманчивый вариант для центров обработки данных и аналитики в реальном времени с огромными объемами данных.
Говоря об аналитических инструментах без нескольких слоев данных или каталогах продукции, разумным может оказаться выбор СУБД MongoDB.
Приложения Интернета вещей и архитектура микросервисов однозначно намекают на внедрение Redis. Конечно, есть и другие СУБД, которые можно рассмотреть, исходя из бизнес-модели и коммерческих потребностей.
Вполне возможно, лучшей рекомендацией будет: следует выбирать ту СУБД, которая лучше всего известна, и с которой наиболее удобно работать.
Известен и альтернативный подход: во многом выбор СУБД зависит от того, что за приложение планируется создать - то есть выбор осуществляет не разработчик, а сам продукт.
Авторы
к.т.н. Драч В.Е.,
к.т.н. Ильичев В.Ю.,
к.т.н. Родионов А.В.
Список литературы
- Драч В.Е., Родионов А.В., Чухраева А.И. Выбор системы управления базами данных для информационной системы промышленного предприятия // Электромагнитные волны и электронные системы. 2018. Т. 23. № 3. С. 71-80.
- Шотов В.С., Клименок К.Г., Соколова А.С., Черненко Д.В. Сравнительная характеристика популярных нереляционных СУБД // В сборнике: Материалы докладов 54-й Международной научно-технической конференции преподавателей и студентов. Материалы докладов конференции. В 2-х томах. Витебск, 2021. С. 30-32.
- Степовик А.Н. Анализ преимуществ и недостатков нереляционных СУБД на примере MONGODB // В сборнике: Научное обеспечение агропромышленного комплекса. 2018. С. 595-597.
- Stack Overflow Developer Survey 2021. [Электронный ресурс] URL: https://insights.stackoverflow.com/survey/2021 (Дата обращения 01.12.2021).
- Ильичев В.Ю. Применение библиотеки OPENCV языка Python для распознавания образов объектов // Системный администратор. 2021. № 7-8 (224-225). С. 130-132.
- Копырин А.С. Универсальная структура базы данных для интеллектуальных цифровых систем // В сборнике: Олимпийское наследие и крупномасштабные мероприятия: влияние на экономику, экологию и социокультурную сферу принимающих дестинаций. Материалы XI Международной научно-практической конференции. 2019. С. 143-146.
- Рубин О.И. Использование СУБД REDIS в качестве промежуточного хранилища данных для POSTGRESQL // StudNet. 2020. Т. 3. № 9. С. 1646-1650.
- Драч В.Е., Ильичев В.Ю., Родионов А.В. АНАЛИЗ ПОПУЛЯРНЫХ НЕРЕЛЯЦИОННЫХ СИСТЕМ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ // Системный администратор. 2022. № 3 (232). С. 84-88.
- Драч В.Е., Ильичев В.Ю. АНАЛИЗ ПОПУЛЯРНЫХ РЕЛЯЦИОННЫХ СИСТЕМ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ // Системный администратор. 2021. № 12 (229). С. 60-65.

Отзывы
Написал Денис
Опубликовано в: Настройка модуля HC-06Написал deman696
Опубликовано в: Настройка модуля HC-06Написал Борис
Опубликовано в: Сравнение современных СУБДНаписал Den
Опубликовано в: Редактирование сейвов Mass Effect 1Написал Артём
Опубликовано в: Запрет обновлений Google Chrome